This tweet regarding a simplified way to use reduce got a lot of attention recently in the JavaScript community.
Simplify your .reduce calls by doing as much work as possible in .filter and .map instead. Compare these two snippets. Which is more readable? Notice that when map arranges data exactly how we want, our .reduce can be just Object.assign.#typescript #javascript pic.twitter.com/3TW57kaCar
— Rupert Foggo McKay (@maxfmckay) May 22, 2021
If you see the replies, you'll find how most people are concerned over the fact that the 2nd method is worse (which also doesn't work as expected, as we'll discuss later in this post) because we are iterating the array thrice when in fact the former one is much slower. After all, the spread operator takes almost O(n) time, resulting in the overall time complexity of O(n2) for the first method. The latter is still O(n) (yes 3 times O(n) is still O(n), measuring 'hot paths' in code for time complexity is worthless) which is far better that O(n2) because of the exponential nature of the latter.
Why is the spread operator so slow?
The speed of the spread operator can vary depending upon how your JavaScript is getting compiled, but for the sake of this article, let's consider it is compiled using the v8 engine, which Node and Chrome use.
So let's assume we have a spread operator like this -
const obj1 = { a: 'hello', b: 'world' }
const obj2 = { ...obj1, c: 'foo' }Not going too deep into the implementation details of how it works, but when you use the spread operator like the above example, the compiler has to do a bunch of stuff like creating a new object literal, iterating and copying the obj1 keys to the new object, and then adding the new keys ( c: 'foo' ).
Let's take this example where we convert an array of objects to an object via reduce -
const arr = [
{ id: 'ironman', name: 'Tony Stark'},
{ id: 'hulk', name: 'Bruce Banner'},
{ id: 'blackwidow', name: 'Natasha Romanoff'},
]
const superheroes = arr.reduce(
(acc, item) => ({
...acc,
[item.id]: [item.name],
}),
{}
);Here the reduce loop runs n times for the array (where n is the number of items in the array). And as we discussed earlier, there is an invisible inner loop here as well with the spread operator that copies the existing accumulator keys to the new object.
Although the inner loop doesn't exactly run n times because it depends on the number of keys currently present in the accumulator, which grows with every iteration of the outer loop.
To simplify the above paragraph, this is how it works -
// First iteration
acc -> {}
{ ...acc, ironman: 'Tony Stark' }// No key needs to be copied
// Second iteration
acc -> { ironman: 'Tony Stark' }
{ ...acc, hulk: 'Bruce Banner' } // 1 key from the accumulator
// would be copied to the new object
// Thrid iteration
acc -> { ironman: 'Tony Stark', hulk: 'Bruce Banner' }
{ ...acc, blackwidow: 'Natasha Romanoff' } // 2 keys from the accumulator
// would be copied to the new object
// ... and so onSo even though the inner loop doesn't exactly run n times on every iteration, it's safe to say that it's in the same class of solutions that execute n2 times, so we can say its O(n2).
But what if you're using some transpiler like Babel or TypeScript's transpiler and targeting ES5 (which we generally do to support older browsers).
Well, first, if you see the specification of the object rest spread proposal on tc39, you will see that -
let ab = { ...a, ...b };
// Desugars to -
let ab = Object.assign({}, a, b); Here, the desugared syntax also has a similar time complexity as the spread operator because it is doing pretty much the same thing, creating a new object and then iterating and copying the keys of the remaining objects to the new object.
Babel transpiles the spread syntax to something similar to the desugared TC39 proposal. Although TypeScripts transpiler creates nested Object.assign calls, which I'm not sure why.
If you want to get into the weeds of what I tried to explain above, you can refer to this awesome article by Rich snapp that covers the same topic in much greater detail.
The better solution
So what is the right way of converting an array to an object like this? Well, there are many ways, and if you see the Twitter thread, you will see a lot of people arguing about how some methods are faster than others. I won't be covering all that, but speaking strictly in terms of time complexity, here is my favorite one -
let result = {}
users.forEach((user) => {
if (user.active) {
result[user.id] = user.name;
}
});In the above method since we are mutating the result object directly the complexity here is O(n), also its more readable as well.
This method using Object.fromEntries is also very neat because Object.fromEntries is built to convert iterables to object.
const filteredUsers = users
.filter((user) => user.active)
.map((user) => [user.id, user.name]);
const result = Object.fromEntries(filteredUsers);Lastly, let's talk about the method that the tweet author suggested. As I mentioned initially, it might look much worse, but 3x O(n) is still O(n), so complexity wise we are probably good. Still, a small mistake leads to a slightly unexpected result and a significantly worse performance.
users
.filter((user) => user.active)
.map((user) => ({ [user.id]: user.name }))
.reduce(Object.assign, {});The problem here is in the reduce call where we directly pass Object.assign to it. If you check the documentation for reduce you'll find that it passes the following arguments to the callback function -
arr.reduce(function(accumulator, currentValue, currentIndex, array) {
// Ommitted for brevity
}, initialValue)So we end up passing all these parameters to Object.assign, which increases the complexity of the operation and returns a slightly weird result. To understand, let's take a look at one of the iterations of the reduce call -
// users = [
// { id: 'id1', name: 'foo', active: true },
// { id: 'id2', name: 'bar', active: true }
// ]
// After the processing data is done by the filter and map
// functions, this gets passed to the Object.assign in the first
// iteration of the reduce
Object.assign({}, { id1: 'foo' }, 0, [{ id1: 'foo' }, { id2: 'bar' }])
// Let's take a look at the arguments being passed -
// First argument is the accumulator which for the first iteration is
// an empty object - {}
// Second argument is the currentValue which is the first item from
// the array generated by the preceding map - { id1: 'foo' }
// Third argument is the currentIndex which represents the index of the
// current item - 0
// Last argument is the array itself which is generated by map in the
// previous step - [{ id1: 'foo' }, { id2: 'bar' }]The first two arguments are what we expected, the third argument being a number doesn't have any effect, the last argument is where the problem starts. Since arrays are also objects in JavaScript, they are also copied via Object.assign with their indexes as the keys. You can view the generated result in this repl.
The correct way would be to pass only required arguments to Object.assign -
users
.filter((user) => user.active)
.map((user) => ({ [user.id]: user.name }))
.reduce((acc, currentValue) => Object.assign(acc, currentValue), {});Jake wrote a really nice article about this pattern explaining why you shouldn't use functions as callbacks unless they're designed for it.
Wait, isn't this premature optimization?
As much as I want to say it is, it's probably not. Since the reduce with spread technique is exponential in nature, it gets gruesome with just a little increase in data.
Take this repl running on Node 12, for example. You can see how the time taken goes from just a couple of milliseconds for 10 times to a few 100 ms for 100 items and a staggering 1-2 seconds for 1000 items. Meanwhile, the difference between the rest of O(n) methods stays under 10ms for all the cases.
The results could be even worse if you're running this on a browser and your users are using some low-powered devices. You could block the main thread and block any interactions for a few hundred milliseconds, resulting in a very laggy UX.
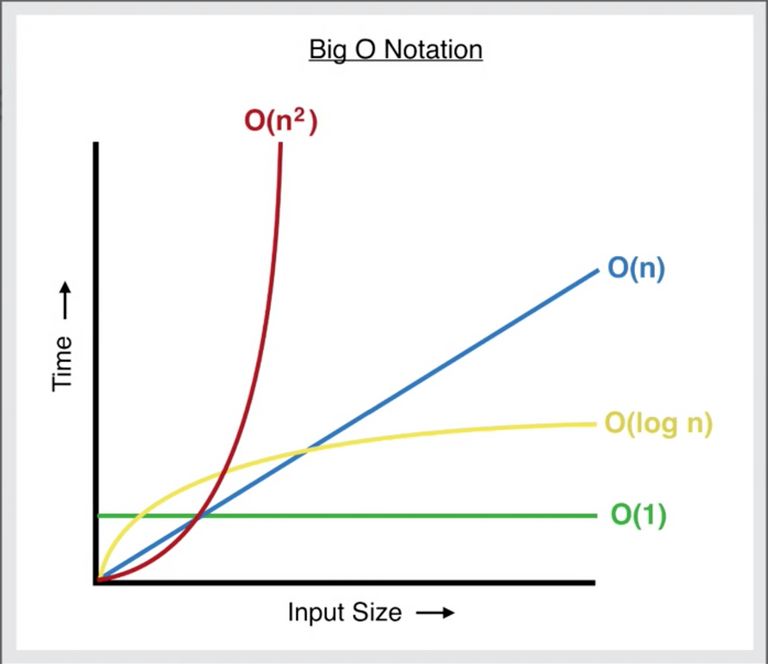
So if we were arguing amongst the O(n) methods that we discussed in the previous section, then that probably would have been a case for premature optimization but not this. Since as its clear from the above graph how the reduce with spread method (with O(n2) complexity) gets considerably worse with the increasing input size.
Conclusion
So, in conclusion, you should try to avoid this pattern in your code, even if you think that the data set is small enough to have any significant impact on performance because you may end up using this method in places where it actually hampers the performance.

